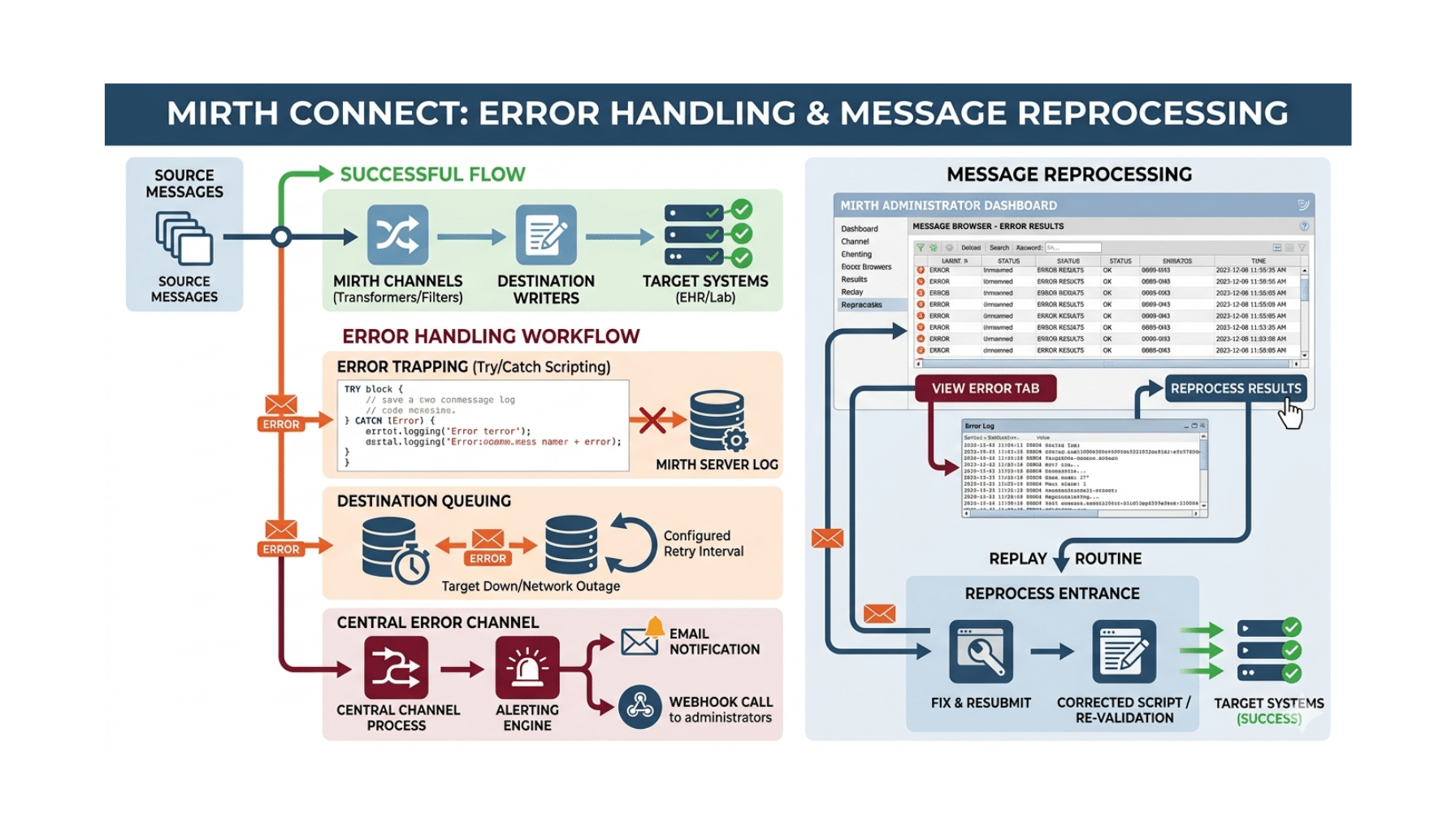
LLM-generated Mirth Connect channels are auto-drafted channel configurations — source connector setup, transformer JavaScript, destination connector setup, filter rules, and routing logic — produced by a large language model from an HL7 v2 sample message and a target downstream system. Production-grade LLM-channel-generation in 2026 requires: RAG over the institution’s existing channel library to match institutional coding conventions, structured generation with Mirth-aware schema enforcement to produce valid channel XML, HIPAA-compliant inference path with BAA paper trail (HL7 sample messages contain PHI), integration with the institution’s engineering pipeline (git workflow, code review, deployment via the Mirth API), test message replay infrastructure that validates generated channels before promotion to staging, and senior-engineer review and approval before production deployment. Most production deployments of this pattern compress what was 4–8 hours of senior engineering work to 30–90 minutes per channel — the engineer’s judgment is still the binding constraint, but the productivity multiplier is real and measurable.
Mirth Connect engineering is one of the highest-leverage candidates for AI augmentation in healthcare integration in 2026. The work is patterned, the institutional knowledge is documented, the cost of senior engineering talent is high, and the use cases are well-defined. LLM-augmented Mirth engineering is one of the higher-ROI, lower-risk healthcare AI deployments — every generated artifact goes through senior-engineer review before production.
This guide is the engineering reference Taction Software® uses on LLM Mirth channel generation engagements.
What Production LLM Channel Generation Does
The reference architecture spans six required components.
Component 1 — RAG Over the Institution’s Existing Channel Library
The customer’s existing channel portfolio is the reference material that ensures generated artifacts match institutional coding conventions, naming standards, error-handling patterns, and operational expectations.
What gets indexed.
- Channel XML configurations for existing channels in production
- Transformer JavaScript code with its institutional patterns (naming conventions, error handling, logging patterns)
- Source and destination connector configurations
- Filter rules and routing logic
- Channel documentation where it exists
How it’s used. At generation time, the LLM retrieves similar existing channels (by message type, vendor, downstream system) and uses them as reference for the new channel. The generated artifact matches the institution’s existing engineering culture rather than producing generic Mirth output.
Without RAG over institutional channels, LLM output is generic — produces channels that work but don’t fit the institution’s existing patterns. Engineering review consumes substantial time bringing the generic output to institutional standards.
Component 2 — Structured Generation with Mirth-Aware Schema Enforcement
Mirth channels have specific XML structure and JavaScript patterns. The LLM’s generation is constrained to produce valid artifacts — invalid channel XML or malformed transformer JavaScript wastes engineering review time.
Implementation patterns.
- JSON schema definition for the channel structure
- Constrained generation (function calling, JSON mode, or structured output APIs) that enforces the schema
- Post-generation validation against Mirth’s actual schema before the artifact is presented to the engineer
- Automatic retry on validation failures with the validation error fed back to the model
Component 3 — HIPAA-Compliant Inference Path
HL7 v2 sample messages contain PHI by definition. The inference path is BAA-covered, encrypted in transit, configured for zero-data-retention, and audit-logged. The full compliance architecture is covered in our HIPAA AI engineering playbook.
Sample messages can be de-identified before AI processing where the use case allows. Most LLM channel generation engagements use de-identified or synthetic samples for the development phase and only flow real PHI under BAA for the production validation steps.
Component 4 — Integration with the Institution’s Engineering Pipeline
Generated channels integrate with the institution’s git workflow, code review process, and deployment pipeline:
- Mirth’s diff-friendly export format for version control
- Code review through the institution’s existing review process (GitHub, GitLab, Bitbucket)
- Deployment via Mirth’s REST API or the management console
- Channel naming conventions matching the institution’s standards
AI tools that produce artifacts outside the institution’s pipeline create technical debt. Production AI Mirth integrates with the existing engineering culture rather than replacing it.
Component 5 — Test Message Replay Infrastructure
Every generated channel ships with synthetic or de-identified test messages that exercise the channel’s logic. Channels are validated against test messages before promotion to staging, and against production-replay traffic (de-identified) before promotion to production.
What this catches.
- Generation errors that produce subtly wrong transformer logic
- Edge cases the LLM didn’t handle (vendor-specific message variants, unusual field combinations)
- Routing logic that doesn’t match the documented requirements
- Output format errors that downstream systems would reject
The test replay infrastructure is what makes the senior-engineer review tractable — the engineer reviews channels that have already passed automated validation, focusing review attention on the harder judgment calls.
Component 6 — Senior-Engineer Review and Approval
Every generated artifact is reviewed, tested, and approved by a senior Mirth engineer before production deployment. The engineer’s judgment about clinical workflow, operational risk, and institutional context is the binding constraint that AI cannot fully replicate in 2026.
What the engineer reviews.
- Does the channel match the institution’s coding conventions?
- Does the transformer handle vendor-specific message variants the LLM may have missed?
- Is the routing logic operationally correct?
- Are error-handling patterns adequate?
- Does the channel fit the institution’s broader integration architecture?
The productivity multiplier from AI augmentation is the compression of generation time, not the elimination of engineer review.
The High-Value Use Cases
Five categories where LLM channel generation produces measurable ROI in 2026.
Use Case 1 — New Vendor Onboarding
Every new lab vendor, every new specialty practice acquired, every new payer integration, every new specialty system requires new Mirth channels. The work is patterned but volume-driven. LLM augmentation compresses the engineering time substantially.
ROI economics. Hospitals running active integration buildouts have the most value capture. A hospital onboarding 15–25 new vendor integrations per year saves substantial senior engineering time — 4–8 hours saved per channel × 100+ channels per year = several hundred engineering hours annually.
Use Case 2 — Channel Maintenance Updates
Existing channels need updates as vendor systems change, payer policies update, or institutional requirements evolve. LLM augmentation produces draft updates the engineer reviews and refines.
ROI economics. Smaller per-update savings than greenfield channel generation, but high volume across the institution’s existing channel portfolio.
Use Case 3 — Documentation Backfill
Many institutions have hundreds of channels with sparse or outdated documentation. The LLM reads channel configurations and generates human-readable documentation; the senior engineer reviews for accuracy.
ROI economics. Documentation backfill at scale was operationally infeasible before AI augmentation. With it, institutions can document hundreds of channels in weeks rather than months.
Use Case 4 — HL7-to-FHIR Migration Acceleration
Institutions migrating from HL7 v2 to FHIR R4 face per-message-type transformation engineering. LLM augmentation produces draft FHIR-compatible mappings; engineers refine for clinical accuracy.
ROI economics. HL7-to-FHIR migration is engineering-intensive; AI augmentation compresses the per-message-type work meaningfully across the institution’s portfolio.
Use Case 5 — Cross-Institution Channel Pattern Transfer
For multi-hospital systems, channel patterns developed at one hospital often need adaptation for other hospitals. LLM augmentation produces draft adaptations that engineers refine for the target institution’s specifics.
ROI economics. Multi-hospital deployments benefit substantially from pattern transfer at AI-accelerated speed.
What Most Teams Get Wrong
Five common patterns that produce LLM Mirth deployments that underperform.
Mistake 1 — Generic LLM Output Without Institutional Grounding
A team uses a foundation LLM to generate channels without RAG over the institution’s channel library. The output is generic; the institution’s coding conventions, naming patterns, and error-handling standards are missing. Engineering review consumes most of the time savings. Resolution: RAG over institutional channels is non-negotiable.
Mistake 2 — No Structured Generation
The LLM produces free-form text that the team has to parse into Mirth channel XML. Parse failures consume engineering time. Resolution: structured generation with schema enforcement.
Mistake 3 — No Test Replay Infrastructure
Generated channels are reviewed by engineers without automated validation. Edge cases slip through review and produce production incidents. Resolution: test message replay before engineer review.
Mistake 4 — PHI Handling Gaps
Sample HL7 messages flow through inference endpoints without BAA coverage. The team discovers the gap at compliance review. Resolution: HIPAA-compliant inference path from week 1.
Mistake 5 — Positioning as Engineer Replacement
The team markets the AI as replacing Mirth engineers rather than augmenting them. Engineers resist adoption; the productivity gains never materialize. Resolution: position as senior-engineer-augmenting tooling. The engineer’s judgment is the binding constraint; the AI’s role is compression of generation time.
Pricing and Engagement Structure
| Engagement | Duration | Price Range | Scope |
| Discovery Sprint | 6 weeks | $45,000–$60,000 | Working LLM channel generation prototype on real institutional channels, eval against senior engineer review, ROI projection |
| MVP Sprint | 8–10 weeks | $80,000–$120,000 | Production-grade architecture, RAG over institutional library, HIPAA-compliant inference, engineering pipeline integration |
| Pilot-Ready Sprint | 12–16 weeks | $130,000–$200,000 | Full institutional deployment, test replay infrastructure, multi-use-case support, operational handoff |
| Production rollout | 16–24 weeks | $150,000–$280,000 | Multi-team deployment, expanded use cases (documentation backfill, FHIR migration support), drift monitoring |
Total LLM Mirth Connect engagement typically runs $250,000–$450,000 across the discovery, MVP, pilot, and production phases.
Closing
LLM-augmented Mirth Connect engineering in 2026 is one of the higher-leverage, lower-risk AI applications in healthcare. The work is patterned, the productivity gains are measurable, and the engineering risk is bounded by senior-engineer review at every step. Institutions with active Mirth engineering needs and senior engineering capacity have a clear AI augmentation case.
If you are scoping LLM-augmented Mirth Connect engineering for your institution, book a 60-minute scoping call. Taction Software has been building Mirth Connect integrations since 2013 — our Mirth practice is older than the AI industry itself. 785+ healthcare implementations, 200+ EHR integrations, zero HIPAA findings on shipped software, and active BAA paper trails with every major AI provider. Our healthcare engineering team is one of the few teams in 2026 with both deep Mirth Connect experience and modern AI engineering depth — exactly the combination LLM Mirth augmentation requires. Our verified case studies cover the production deployments behind these patterns. For the engineering scope behind the engagement, see our healthcare software development practice and our hospital and health-system practice for the operational context. For the data integration patterns this work depends on, see our healthcare data integration practice. For an estimate against your specific use case, see the healthcare engineering cost calculator.