A sepsis early-warning model is a clinical AI system that predicts the probability of sepsis onset within a near-term clinical window from real-time inpatient or ED data — vital signs (HR, BP, temp, RR, SpO2), lab results (lactate, white count, creatinine, bilirubin, platelet count), suspected infection signals, SOFA component features, antibiotic administration patterns, and clinical context. Production-grade sepsis early-warning systems in 2026 require: real-time feature engineering against streaming clinical data, FDA SaMD-aligned validation methodology (most sepsis early-warning systems are Class II 510(k)-cleared medical devices), rigorous clinical-safety design (sensitivity for true sepsis is the binding constraint; alert fatigue is the most common deployment failure), integration with the institution’s clinical workflow (alert routing, on-call escalation, documentation linkage), per-population calibration (model performance varies substantially across hospital units, patient demographics, and clinical severity), drift monitoring with quarterly clinical-safety review, and audit logging across the prediction-to-clinical-action cycle. The economics: a 4–6 hour earlier sepsis recognition reduces mortality 5–15%, reduces length of stay 1–2 days, avoids 10–20% of avoidable ICU transfers — annual value at a 400-bed hospital with ~1,500 sepsis cases typically lands at $5M–$15M.
Sepsis early-warning is one of the highest-stakes clinical AI use cases. The clinical impact is direct (mortality reduction is well-documented in published studies); the economic impact is large; the regulatory pathway is well-established (multiple FDA-cleared sepsis early-warning systems in production use). It is also one of the use cases where engineering depth matters most — production failures here have direct patient-safety implications.
This guide is the engineering reference Taction Software® uses on sepsis early-warning model engagements.
What Production Sepsis Early-Warning Systems Do
The reference architecture spans eight required components.
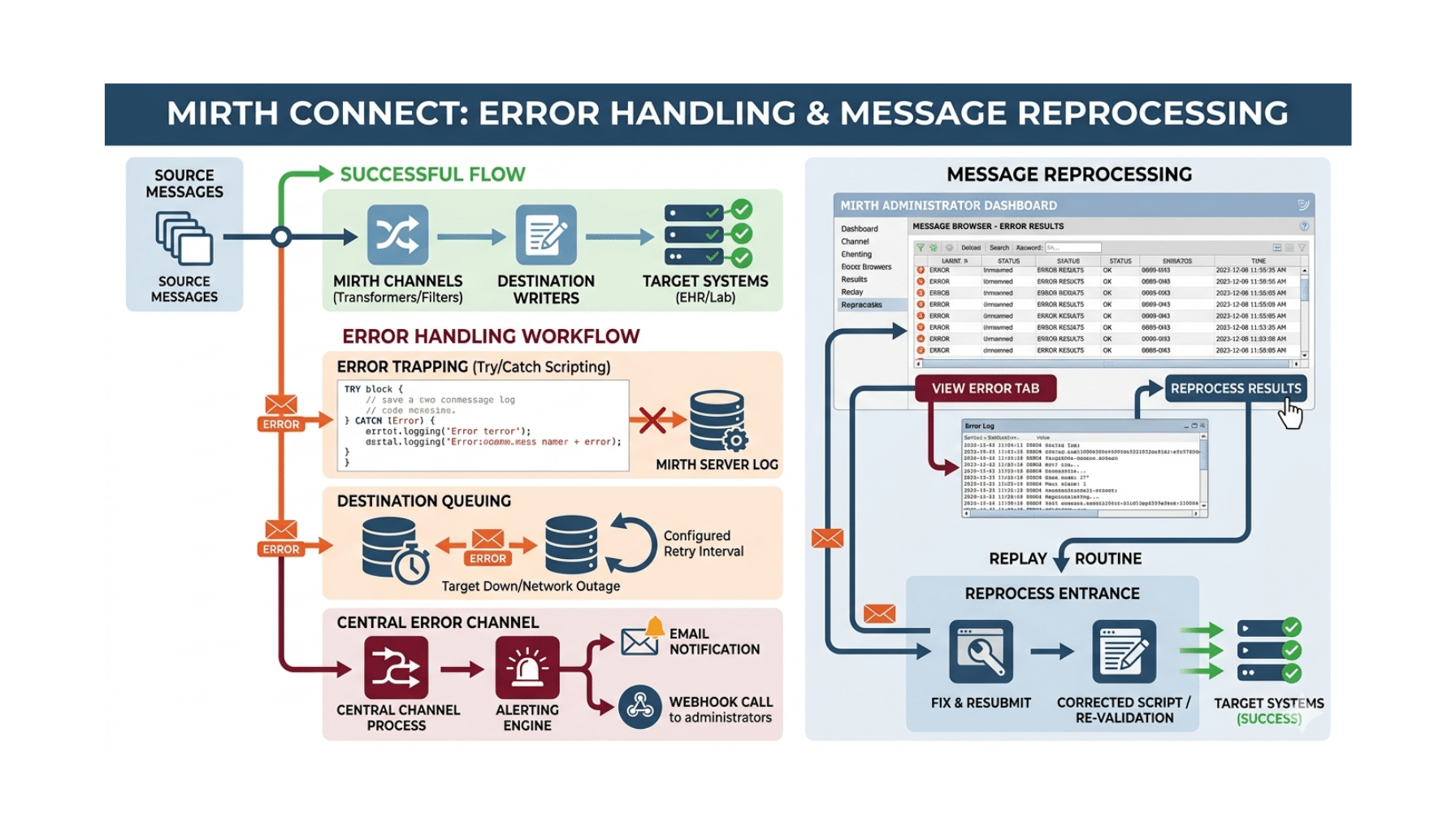
Component 1 — Real-Time Feature Engineering
The model operates on streaming clinical data. Vital signs update minute-by-minute; labs arrive in batches as they’re resulted; clinical events (antibiotic administration, fluid bolus, vasopressor initiation, ICU transfer) arrive asynchronously.
The feature engineering layer:
- Streams real-time vital signs from the EHR or patient monitors
- Polls labs as they’re resulted
- Maintains rolling windows of feature values for time-series modeling
- Computes derived features (SOFA components, qSOFA, NEWS2, MEWS, institution-specific scoring)
- Handles missing data and measurement artifacts (sensor errors, transcription errors, value clipping)
- Triggers prediction updates as features change
The infrastructure for real-time feature engineering is more involved than batch-prediction patterns used in readmission or no-show models.
Component 2 — Time-Series Predictive Modeling
The model’s input is the patient’s recent clinical trajectory, not just current values. A patient with stable vital signs at low absolute values is different from a patient whose vital signs are deteriorating from elevated values toward those same low values.
Production architecture patterns.
- Gradient boosting on engineered time-series features — strong baseline, interpretable, fast inference.
- Recurrent neural networks (LSTM/GRU) — natural fit for sequence modeling but with diminishing returns and harder validation.
- Transformer-based time-series models — emerging in 2025–2026; show promise for complex temporal patterns but less mature in clinical deployment.
- Hybrid architectures — GBM as primary predictor with neural-network components for specific feature types.
The architecture choice matters less than rigorous validation. Multiple FDA-cleared sepsis early-warning systems use simpler architectures with rigorous validation; some research deployments with sophisticated architectures fail clinical-safety review.
Component 3 — FDA SaMD-Aligned Validation
Sepsis early-warning is firmly in FDA SaMD territory. The validation methodology aligns with FDA expectations for AI medical devices — pre-specified protocol, gold-standard label adjudication, held-out test set, subgroup performance, calibration, decision-curve analysis, external validation. Multiple sepsis early-warning systems have achieved 510(k) clearance through this methodology.
Specific validation requirements for sepsis.
- Gold-standard adjudication — sepsis cases adjudicated by intensivists or critical-care specialists using consensus definitions (Sepsis-3 criteria most commonly).
- Time-window analysis — performance reported at multiple prediction horizons (4 hours, 6 hours, 12 hours before sepsis onset).
- Sensitivity at clinical thresholds — the threshold the deployment will use, with sensitivity, specificity, and lead time reported.
- Subgroup performance — across age, sex, race/ethnicity, and clinical strata (medical vs. surgical, immunocompromised vs. immunocompetent, etc.).
- External validation — typically required for FDA submission.
- Real-world performance monitoring — post-deployment performance tracking is part of the FDA submission’s PCCP commitment.
Component 4 — Alert-Fatigue Management
Alert fatigue is the most common production failure mode for sepsis early-warning. Alert thresholds tuned without alert-fatigue consideration produce 50+ alerts per shift; clinicians stop reading them within 2–3 weeks.
Production patterns.
- High-specificity threshold tuning — high specificity at the cost of some sensitivity, with the sensitivity loss balanced by earlier prediction horizon.
- Alert escalation hierarchy — moderate-risk alerts to nursing; high-risk alerts to rapid-response team; very-high-risk alerts to ICU consultation.
- Per-unit threshold tuning — different thresholds for medical floor vs. surgical floor vs. ED vs. ICU based on baseline sepsis prevalence and clinical-team capacity.
- Suppression for already-treated patients — the model doesn’t fire alerts for patients already receiving sepsis treatment.
- Alert volume monitoring — per-clinician alert counts tracked weekly; outliers reviewed for threshold adjustment.
Component 5 — Clinical Workflow Integration
The model’s predictions reach clinicians through the institution’s existing alerting and clinical-workflow infrastructure:
- EHR alert system (Epic Best Practice Advisories, Cerner-Oracle equivalent)
- Secure messaging to on-call clinicians
- Rapid-response team notification systems
- Mobile alert applications used by clinical staff
- Documentation prompts for clinical action
Standalone sepsis dashboards in separate web applications get ignored. In-EHR alerting that fits the institution’s existing on-call workflow is what gets clinical engagement.
Component 6 — Per-Population Calibration
Sepsis prevalence and presentation vary substantially across populations. ICU sepsis is different from medical-floor sepsis is different from ED sepsis. Per-population calibration is essential; deployment patterns include:
- Calibration on the institution’s specific data before production deployment
- Per-unit calibration where the institution operates clinically distinct units
- Recalibration after major clinical-practice changes (new antibiotic stewardship protocols, new sepsis bundles)
Component 7 — Drift Monitoring with Clinical-Safety Review
Production sepsis models drift. Patient population shifts, clinical practice evolves, antibiotic stewardship changes affect signal-to-noise ratios. Drift monitoring catches degradation:
- Input distribution drift on key features
- Prediction distribution drift
- Performance drift as outcomes accumulate (sepsis labels arrive within 1–7 days of prediction)
- Alert-action concordance (are alerts producing clinical action consistent with sepsis suspicion)
Quarterly clinical-safety review formalizes the response — model updates, threshold adjustments, or in extreme cases, model deployment pause.
Component 8 — Audit Logging
Every prediction event, every alert fired, every clinician interaction with the alert, every downstream clinical action is logged. The audit trail is critical for clinical-safety investigation when adverse events occur and for post-market surveillance under the FDA SaMD pathway.
Build vs. Buy for Sepsis Early-Warning
The sepsis early-warning vendor landscape includes several FDA-cleared products. The buy-vs-build decision turns on five factors:
Factor 1 — Patient population fit. Vendor models trained on national populations may underperform on local populations, particularly at specialty hospitals (oncology centers, cardiac specialty hospitals, behavioral health) or institutions with unusual patient mixes. Local-population calibration is the minimum step regardless of build-vs-buy.
Factor 2 — Integration depth. Vendor products vary in EHR integration maturity. Deep integration with Epic Best Practice Advisories, Cerner-Oracle alerting infrastructure, or athenaOne is operationally easier with vendors who already have it. Custom integration is engineering-intensive.
Factor 3 — Customization needs. Institution-specific protocols, alert routing logic, escalation hierarchies, and clinical workflow patterns favor custom builds. Standardized institutional patterns favor off-the-shelf.
Factor 4 — FDA pathway control. Custom builds give the institution full control over the FDA pathway and the predicted change-control plan. Vendor products have vendor-controlled PCCP boundaries.
Factor 5 — Operational ownership. Vendor products come with vendor-managed operations. Custom builds require institutional operational ownership including ongoing FDA submission maintenance.
For most general acute-care hospitals, vendor-supplied FDA-cleared products are the right answer with local-population calibration. For specialty hospitals, academic medical centers building proprietary AI capability, or institutions requiring on-prem deployment, custom builds win.
Pricing and Engagement Structure
| Engagement | Duration | Price Range | Scope |
| Discovery Sprint | 6–8 weeks | $45,000–$60,000 | Working sepsis prediction prototype on retrospective data, eval methodology aligned with FDA expectations, ROI projection |
| MVP Sprint | 10–12 weeks | $130,000–$170,000 | Production-grade model with real-time feature engineering, FDA-aligned validation, BAA paper trail, audit logging |
| Pilot-Ready Sprint | 16–20 weeks | $200,000–$280,000 | Full clinical workflow integration, alert-fatigue management infrastructure, controlled pilot deployment |
| FDA SaMD Pathway | 9–18 months parallel | $200,000–$500,000+ | Pre-submission engagement, validation execution, 510(k) submission preparation, PCCP development |
| Production rollout | 24–48 weeks | $300,000–$600,000+ | Full multi-unit deployment, multi-site if applicable, post-market surveillance infrastructure |
Total sepsis early-warning engagement runs $700,000–$1.5M+ for FDA-track custom builds. Off-the-shelf vendor product deployment with calibration runs $200,000–$400,000 substantially lower because the FDA pathway and base validation are vendor-handled.
Closing
Sepsis early-warning is one of the highest-stakes healthcare AI use cases — and one of the most production-mature when engineering depth is rigorous. The architecture spans real-time feature engineering, FDA SaMD-aligned validation, alert-fatigue management, and clinical workflow integration. Buyers and vendors who scope against this depth produce deployments that survive clinical-safety review and produce measurable mortality reduction.
If you are scoping a sepsis early-warning deployment, book a 60-minute scoping call. Taction Software has shipped 785+ healthcare implementations since 2013, with 200+ EHR integrations across Epic, Cerner-Oracle, Athena, and Allscripts, zero HIPAA findings on shipped software, and active BAA paper trails with every major AI provider. Our healthcare engineering team builds production sepsis early-warning systems with the architecture described above as default scope; for FDA submission scope, we partner with specialist regulatory consultants. Our verified case studies cover the production deployments behind these patterns. For the engineering scope behind the engagement, see our healthcare software development practice and our hospital and health-system practice for the operational context. For the data integration patterns this work depends on, see our healthcare data integration practice. For an estimate against your specific use case, see the healthcare engineering cost calculator. For deeper context, see our broader generative AI healthcare applications work.