An AI triage copilot for emergency departments is a clinical AI system that reads the patient’s chief complaint, vitals, history snippet, and reason-for-visit text, and drafts a disposition recommendation — emergent / urgent / routine — with a recommended Emergency Severity Index (ESI) level, a recommended initial workup, and a rationale citing the relevant institutional triage protocol or clinical guideline. The triage copilot operates under the human-in-the-loop pattern: the triage nurse reviews the draft, accepts, edits, or rejects, and the final disposition is the nurse’s. Production-grade AI triage copilots in 2026 require: structured ingestion of patient presentation data, RAG over institutional triage protocols, citation-grounded disposition drafting, hard guardrails on emergent presentations (near-zero false-negative tolerance for stroke, MI, sepsis, trauma), in-EHR integration with the worklist priority logic, and audit logging of every override decision. The clinical impact at scale is measurable: 10–15% reduction in ED throughput time, improved triage consistency across nurses, and earlier identification of high-acuity presentations.
ED triage is one of the highest-leverage clinical AI use cases in 2026 — high volume (millions of encounters per year per major US health system), high consistency variance (different nurses produce different dispositions on similar presentations), and high downstream impact (the disposition determines length of stay, resource allocation, and clinical urgency for the next 4–8 hours of care).
This guide is the engineering reference Taction Software® uses on ED triage copilot engagements.
What Production-Grade AI Triage Copilots Do
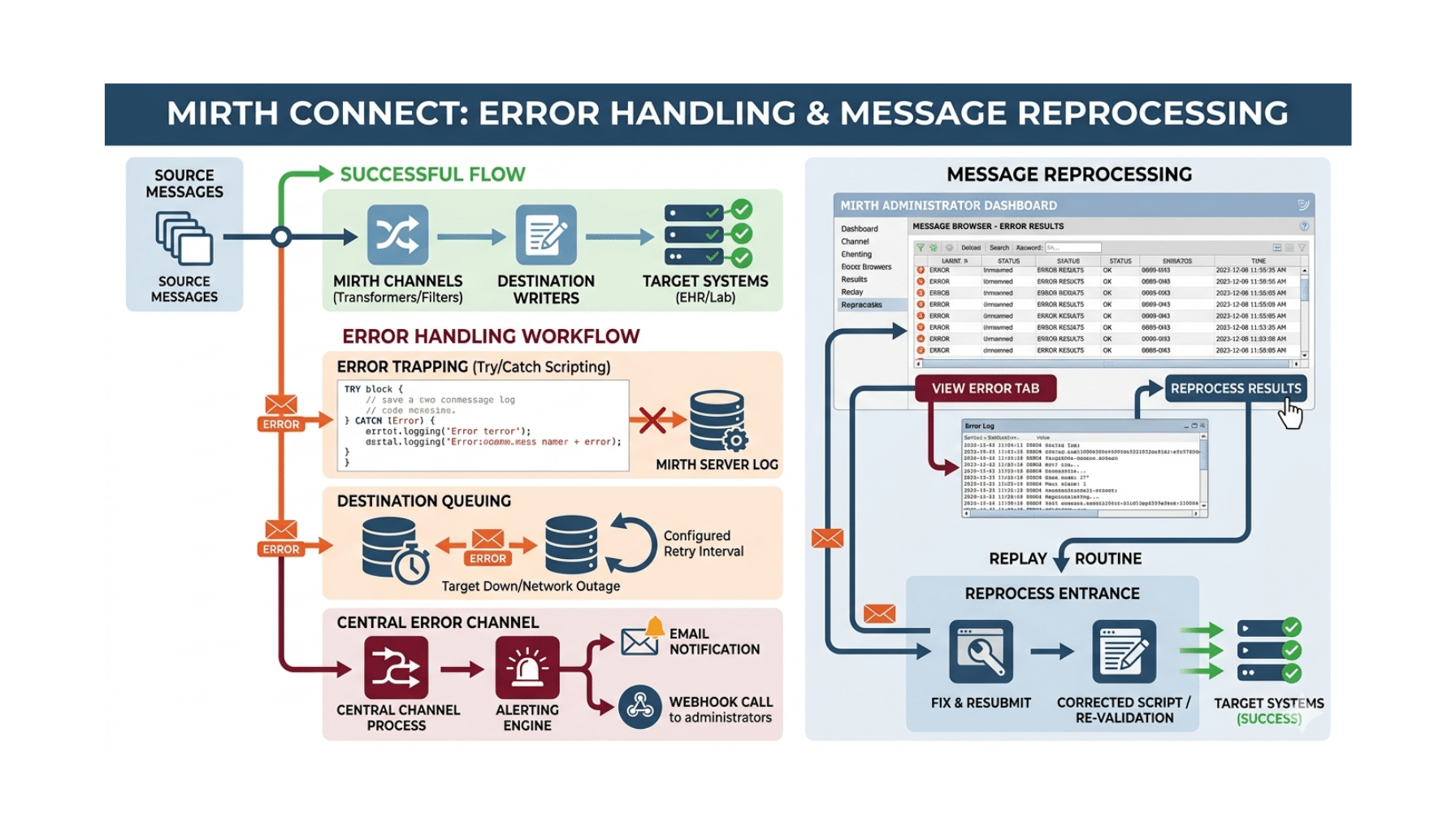
The reference architecture spans six capabilities.
Structured ingestion of patient presentation data. Chief complaint, vitals (HR, BP, temp, SpO2, RR), patient demographics, brief history (key conditions, recent medications, allergies), and reason-for-visit narrative. Data flows from the ED’s intake system or directly from FHIR Observation/Condition resources.
Citation-grounded RAG over institutional triage protocols. The institution’s specific ESI guidelines, departmental protocols for high-acuity presentations (stroke, STEMI, sepsis, trauma), and any institutional fast-track criteria. Generic ESI logic without institutional grounding produces dispositions clinicians override.
LLM-drafted disposition with rationale. The model produces the recommended ESI level, the recommended workup pathway, and the rationale citing the protocol that drove the recommendation. The rationale is reviewable by the triage nurse before acceptance.
Hard guardrails on emergent presentations. Sensitivity for stroke, STEMI, sepsis, severe trauma, and pediatric high-acuity has near-zero false-negative tolerance. Pattern-based fast-fail rules (chest pain in 60+ year old → emergent regardless of LLM output; suspected stroke symptoms → emergent regardless; vitals consistent with sepsis → emergent regardless) backstop the LLM reasoning.
In-EHR integration with worklist priority. The disposition writes back to the EHR as a structured field; the worklist priority updates accordingly. Standalone triage AI in a separate web app produces clinician complaints; in-EHR integration is non-negotiable.
Audit logging of every override decision. Accept/edit/reject decisions are first-class log events. Override patterns reveal model failure modes and inform quarterly tuning.
The Five Engineering Decisions
Five decisions drive the production quality of an ED triage copilot.
Decision 1 — How Aggressive on Sensitivity vs. Specificity
The fundamental trade-off in any triage system. ED triage is asymmetric: the cost of under-triaging an emergent presentation (delay to definitive care) is much higher than the cost of over-triaging (queue resource consumed unnecessarily). The threshold tuning has to reflect this asymmetry.
The production pattern. Tune for sensitivity > specificity in the high-acuity presentations. False positives in ESI 1/2 (over-triage) are operationally tolerable; false negatives are not. The hard-guardrail layer enforces this for the categories where the consequences of false negatives are most severe.
Decision 2 — How to Handle the Model’s Reasoning Chain on Atypical Presentations
ED presentations include atypical cases — atypical chest pain, atypical stroke (especially in older women, where stroke can present as confusion or weakness rather than classic deficit), atypical pediatric presentations. Off-the-shelf LLM reasoning trained on textbook cases can miss these.
The production pattern. The institutional protocol corpus includes documented atypical-presentation patterns. The retrieval is configured to surface atypical-presentation guidance for the relevant patient demographics. The eval test set includes atypical cases at higher density than their natural prevalence to validate model behavior.
Decision 3 — How to Integrate with the Existing ESI Framework
The Emergency Severity Index is the dominant US triage system. Most US EDs use ESI 5-level triage. The AI’s output has to fit cleanly inside this framework — not introduce a parallel system clinicians have to translate.
The production pattern. The AI’s recommended disposition is expressed as an ESI level (1-5) with the ESI-aligned justification. The output rendering matches the institution’s existing ESI documentation. The integration is additive to ESI, not replacement of it.
Decision 4 — How to Handle Pediatric, Behavioral Health, and Specialty Populations
ED triage is heterogeneous. Pediatric triage, behavioral health triage, OB triage, and trauma triage all have specialty-specific protocols and presentation patterns. A general ED triage AI that doesn’t handle these correctly produces clinician complaints fast.
The production pattern. Population-specific routing in the inference gateway. Pediatric presentations route to a pediatric-specific protocol corpus and prompt structure. Behavioral health presentations route to behavioral-health-specific protocols including crisis-detection patterns. The architecture supports specialty patterns rather than treating ED triage as a single use case.
Decision 5 — How Fast Does the Output Need to Be
ED triage is time-pressured. The triage nurse is moving through patients; AI that takes 30 seconds to produce output disrupts workflow. Sub-3-second latency is the operational floor; sub-1-second is the target.
The production pattern. Mid-tier model (Claude Sonnet, GPT-4o) for the dispositional reasoning; small fast model for the initial classification. RAG retrieval optimized for low latency. Pre-computed institutional protocol embeddings reduce retrieval time.
Eval Methodology for ED Triage AI
The validation methodology that distinguishes production-grade ED triage AI from research-paper triage AI.
Frozen test set. 500–1,500 representative ED presentations. Stratified to include high-acuity presentations at sufficient density (oversampling stroke, STEMI, sepsis, trauma, pediatric high-acuity). Time-spread to avoid seasonality bias.
Gold-standard adjudication. Each case is reviewed by two ED clinicians independently. Disagreements adjudicated by a third reviewer. The gold-standard label is the ESI level the case actually warranted, not the disposition that was given in production (which can include errors).
Performance metrics.
- Agreement with gold-standard ESI level (Cohen’s kappa, ≥ 0.7 is the production target)
- Sensitivity for ESI 1/2 (≥ 95% — false negatives in emergent presentations are unacceptable)
- Specificity overall (positive predictive value of ESI 1/2 calls)
- Subgroup performance across age, gender, race/ethnicity, and presentation category
- Latency distribution (p50, p95, p99)
Override-rate tracking in production. Real-world override patterns are the most informative signal. Rising override rate is a leading indicator of model degradation; clustered overrides on specific presentation types reveal training-data gaps.
External validation. For institutions deploying multi-site, validation on data from sites not represented in the training corpus catches site-specific drift.
Pricing and Engagement Structure
The 2026 production pricing for AI ED triage copilot engagements.
| Engagement | Duration | Price Range | Scope |
| Discovery Sprint | 4–6 weeks | $45,000 | Working triage copilot prototype on real ED data, eval against frozen test set, validation report, production-readiness assessment |
| MVP Sprint | 8 weeks (cumulative $95K) | $95,000 cumulative | Production-grade architecture, BAA paper trail, audit logging, clinician override workflow, in-EHR launch context |
| Pilot-Ready Sprint | 12 weeks (cumulative $145K) | $145,000 cumulative | Full EHR integration with worklist priority write-back, pilot deployment scope, change-management infrastructure |
| Production rollout | 16–32 weeks | $200,000–$450,000 | Full multi-site deployment, multi-EHR integration, operational support, drift monitoring, quarterly eval refresh |
The Pilot-Ready Sprint is the most popular tier among hospital ED leadership teams. The architecture is production-grade; the deployment is to a defined pilot population; the measurement methodology supports the rollout decision.
Closing
ED triage AI in 2026 is a production-mature category with measurable clinical and operational impact. The engineering depth required — RAG over institutional protocols, hard guardrails on emergent presentations, sub-second latency, EHR-integrated workflow — is substantial but well-defined. Buyers who scope against this engineering depth produce deployments that survive clinical-safety review and clinician adoption. Buyers who scope against generic LLM capability produce demos that don’t translate.
If you are scoping an ED triage copilot for your hospital or health system, book a 60-minute scoping call. Taction Software has shipped 785+ healthcare implementations since 2013, with 200+ EHR integrations across Epic, Cerner-Oracle, Athena, and Allscripts, zero HIPAA findings on shipped software, and active BAA paper trails with every major AI provider. Our healthcare engineering team builds production triage copilots with the architecture described above as default scope. Our verified case studies cover the production deployments behind these patterns. For the engineering scope behind the engagement, see our healthcare software development practice and our hospital and health-system practice for the operational context. For the data integration patterns this work depends on, see our healthcare data integration practice. For an estimate against your specific use case, see the healthcare engineering cost calculator. For deeper context, see our broader generative AI healthcare applications work.