Three customization techniques are used to adapt foundation language models to healthcare-specific use cases: prompt engineering (writing system prompts and few-shot examples that shape model behavior without changing the model itself), retrieval-augmented generation (grounding model output in retrieved documents from a domain-specific corpus), and fine-tuning (updating model weights on healthcare-specific training data). Each technique has different cost economics, different production maturity, different compliance implications, and different use-case fit. The 2026 production decision framework: start with prompt engineering, add RAG when the use case requires institutional grounding, consider fine-tuning only when prompt engineering and RAG are insufficient. Most production healthcare AI uses prompt engineering plus RAG; fine-tuning is reserved for narrow use cases where both are demonstrably inadequate. The wrong default — fine-tuning first because it sounds technically sophisticated — produces engagements that take 4–6x longer, cost 5–10x more, and often underperform a well-engineered RAG architecture.
The customization decision in healthcare LLMs has matured substantially. The 2024 question was “should we use foundation models or train our own”; the 2026 question is “given that we’re using foundation models, which customization technique is right for this use case.” The wrong answer at this question is the most expensive technical decision in many healthcare AI engagements.
This guide is the customization decision framework Taction Software® applies on every engagement. It covers the three techniques, the decision framework, the failure modes when teams pick wrong, and the implementation patterns for each.
The Three Techniques
Prompt Engineering
The model is unchanged. Customization happens in the prompt — the system instruction, the input format, the few-shot examples, the output schema specification. The model’s behavior is shaped by what’s in the context window at inference time.
Strengths.
- Fast to iterate. Changes ship in minutes.
- Cheap. No training infrastructure required.
- Reversible. Revert to a prior version of the prompt without retraining anything.
- Works with any frontier model.
- No HIPAA implications beyond standard inference (no training-data PHI considerations).
Weaknesses.
- Limited capacity. The context window holds a finite amount of guidance.
- Stochastic behavior. Subtle prompt changes can produce subtle behavior changes that show up in production rather than testing.
- Doesn’t add capability. The model’s underlying knowledge is unchanged.
Where prompt engineering wins. Most healthcare AI use cases benefit from rigorous prompt engineering as the default customization technique. The technique is mature, well-documented, and produces production-grade outputs across most clinical AI use cases when the institutional knowledge required fits inside a reasonable context window.
Retrieval-Augmented Generation (RAG)
The model is unchanged. Customization happens through retrieval — at inference time, a retrieval system pulls relevant documents from a corpus and injects them into the prompt. The model produces output grounded in the retrieved context.
Strengths.
- Adds institutional knowledge to the model without training. The corpus is the institution’s specific guidelines, protocols, formulary, chart text, etc.
- Citations are natural — every claim in the output can reference a specific source document.
- Updates to the corpus take effect immediately. New guidelines, new formulary entries, new protocols enter the system without retraining.
- Scales to large corpora. Vector databases handle millions of documents.
- Works with any frontier model.
- Manageable HIPAA implications. The retrieval system is a PHI store with the same compliance requirements as any other.
Weaknesses.
- Retrieval quality matters. Bad retrieval produces irrelevant context, which produces bad output. Retrieval engineering is non-trivial.
- Latency adds. Retrieval steps add 100–500ms typically.
- Complex queries require complex retrieval. Multi-step retrieval, reranking, hybrid search add engineering investment.
- Corpus curation is operational work. The corpus has to be maintained, updated, and validated over time.
Where RAG wins. Use cases where the model’s output has to ground in institution-specific or domain-specific content that wouldn’t fit in a static prompt. Clinical copilots referring to institutional guidelines. Coding suggestions citing institutional coding policies. Patient messaging using institutional clinical content. Most production healthcare AI in 2026 uses RAG as the dominant customization pattern.
Fine-Tuning
Model weights are updated through training on healthcare-specific data. The fine-tuned model has different behavior than the base model — it’s been adapted to the use case at the weights level.
Strengths.
- Persistent behavior change. The fine-tuned model behaves the way the training data taught it, without needing prompt engineering on every inference.
- Can encode capability the base model lacks. For specialty clinical reasoning where the base model is weak, fine-tuning can close the gap.
- Inference is sometimes cheaper. A fine-tuned smaller model can outperform a larger model on the specific use case, with lower inference cost.
Weaknesses.
- Expensive to develop. Training data preparation, fine-tuning runs, validation across versions all add up. Healthcare-specific fine-tuning typically runs $50,000–$200,000+ in engineering investment.
- Slow to iterate. Each round of fine-tuning takes days to weeks; prompt engineering takes minutes.
- HIPAA implications. PHI in the training data has to be addressed (de-identification, consent, retention). The fine-tuned model itself can be PHI-derivative under specific attack conditions.
- BAA scope changes. Fine-tuning APIs are sometimes covered under BAA, sometimes not, depending on the model and the contract revision.
- Fine-tuned model versions need separate validation. Each new fine-tune is essentially a new model that has to be re-evaluated.
- Risk of catastrophic forgetting. The fine-tuned model can lose capability the base model had.
Where fine-tuning wins. Narrow use cases where prompt engineering and RAG are demonstrably insufficient — typically because the use case requires reasoning patterns, specialty knowledge, or output styles the base model doesn’t produce. Specialty clinical reasoning where the base model lacks domain depth. High-volume use cases where the cost of running a fine-tuned smaller model beats the cost of running the frontier model. Specific output formats where prompt engineering can’t reliably produce the format.
The Decision Framework
The decision framework Taction’s engineering team applies on every customization decision.
Step 1 — Start with rigorous prompt engineering. System prompts, few-shot examples, output schemas, structured generation. Iterate over a 1–2 week period with eval against real data. Most use cases are solvable here.
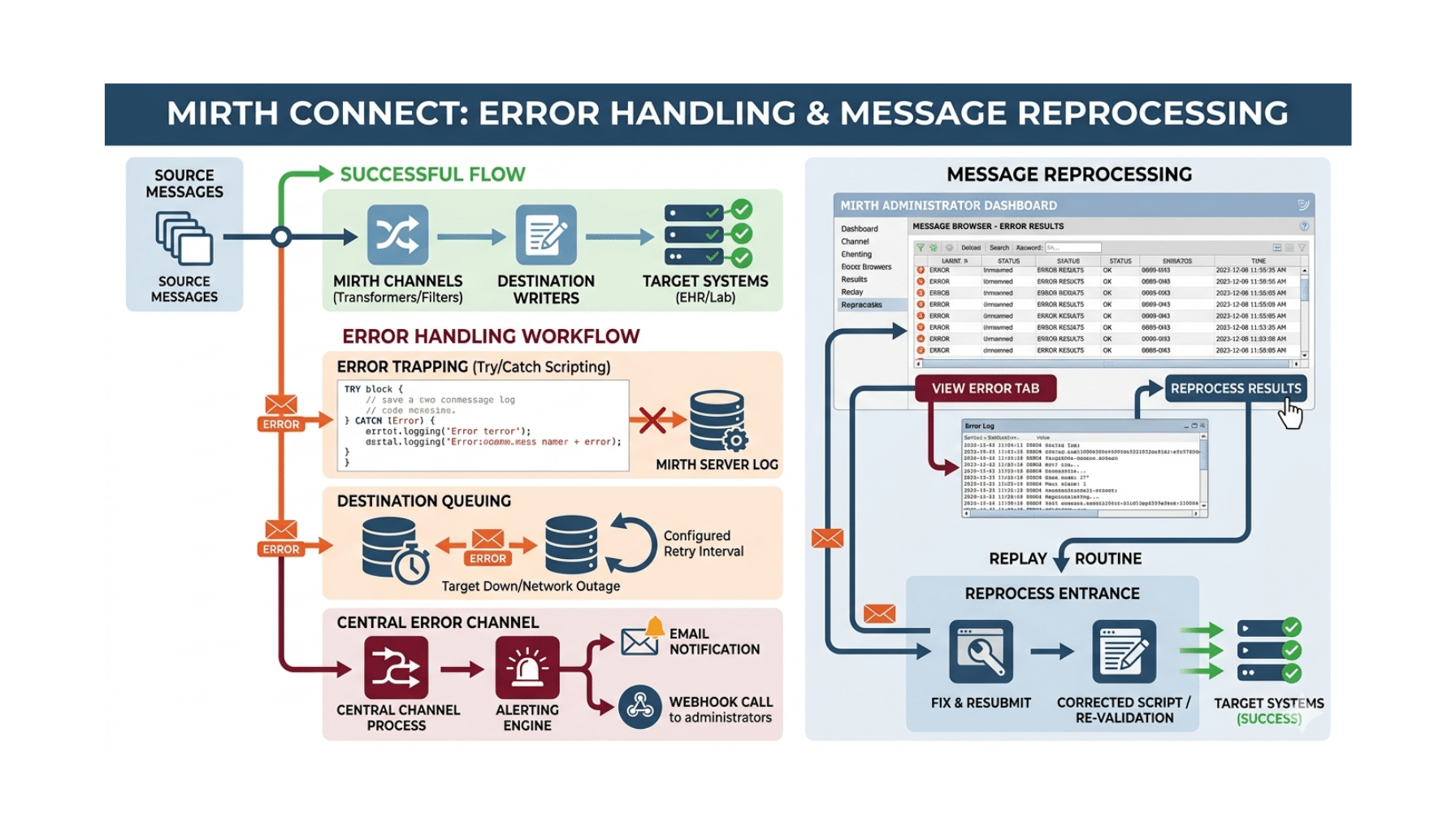
Step 2 — Add RAG when the use case requires institutional grounding. If the model needs to cite specific institutional guidelines, refer to specific protocols, or operate against the institution’s specific corpus, RAG is the right next step. Add it on top of prompt engineering, not as a replacement.
Step 3 — Consider fine-tuning only when prompt engineering and RAG are demonstrably insufficient. Run the eval after rigorous prompt engineering plus well-engineered RAG. If the metrics still don’t meet the threshold, consider fine-tuning. The “demonstrably insufficient” bar is non-trivial — most teams that thought they needed fine-tuning discover that better prompt engineering or better retrieval would have closed the gap.
Step 4 — When fine-tuning, plan for the operational cost. Fine-tuning is not a one-time investment. The fine-tuned model has to be re-validated when the base model updates, when the training data evolves, and when the use case shifts. The operational cost compounds.
The decision tree is simple: prompt engineering → add RAG → consider fine-tuning. Most production healthcare AI ends at step 2 with prompt engineering plus RAG. Step 3 is rare and reserved for narrow specialty cases.
Cost Comparison
The 2026 cost economics across the three techniques.
Prompt Engineering
- Initial development. 1–2 weeks of senior engineer time. Cost: $5,000–$15,000 for a moderately complex use case.
- Iteration. Hours to days per cycle. Cost: $1,000–$5,000 per major iteration.
- Inference cost. Standard model API pricing. No additional overhead.
- Total first-year cost (typical use case). $10,000–$30,000 in engineering, plus standard inference cost.
RAG
- Initial development. 4–8 weeks of engineering effort, including corpus preparation, retrieval infrastructure, retrieval engineering, and integration. Cost: $40,000–$100,000.
- Corpus maintenance. Ongoing operational work. Cost: $1,000–$5,000 per month at moderate scale.
- Inference cost. Model API plus vector database query overhead. Roughly 1.2–1.5x the cost of equivalent prompt-engineered inference.
- Total first-year cost (typical use case). $60,000–$150,000 in engineering, plus inference cost slightly above prompt-engineering.
Fine-Tuning
- Initial development. 8–16 weeks of engineering effort, including training data preparation, de-identification, fine-tuning infrastructure, training runs, validation, and integration. Cost: $80,000–$250,000+.
- Re-tuning over time. Each major re-tune (typically 2–4x per year for a production fine-tuned model) costs $10,000–$50,000.
- Inference cost. Variable. Fine-tuned smaller models can be cheaper per inference than frontier models; fine-tuned larger models are typically more expensive than non-fine-tuned equivalent.
- HIPAA infrastructure overhead. Training data de-identification, training data retention, model versioning, BAA scope review. Cost: $20,000–$60,000 over the project.
- Total first-year cost (typical use case). $150,000–$400,000+ in engineering and infrastructure.
The cost ratio across the three techniques is roughly 1x (prompt engineering) : 5–10x (RAG) : 15–30x (fine-tuning). The accuracy gain across them on most use cases is roughly 1.0x : 1.2–1.5x : 1.05–1.3x — meaning RAG produces large accuracy gains over prompt engineering, while fine-tuning often produces marginal additional gains over RAG at much higher cost.
This is the core economic argument. RAG typically produces the best accuracy-per-dollar across most healthcare AI use cases. Fine-tuning is reserved for the cases where the accuracy gain over RAG is large enough to justify the cost increase.
When Each Technique Wins
Prompt Engineering Wins When
- The use case is well-defined and the institutional guidance fits in a static prompt.
- The required behavior can be specified in instructions and few-shot examples.
- Iteration speed matters more than absolute peak accuracy.
- The use case is exploratory or early-stage and the architecture is still evolving.
Typical examples. Patient messaging draft responses with standard institutional tone. Triage disposition with simple protocol logic. Summary generation for well-structured input.
RAG Wins When
- The use case requires grounding in institutional content (guidelines, protocols, formulary, chart text).
- Citation accuracy matters (clinical claims must reference source documents).
- The corpus changes over time (new guidelines, new policies) — RAG updates immediately, fine-tuning requires re-tuning.
- The corpus is large enough that prompt engineering can’t include all relevant context in a single prompt.
- The accuracy gap from prompt engineering alone is large.
Typical examples. Clinical copilots citing institutional guidelines. Coding assistance with institutional coding policy. Prior-auth letter drafting with payer-specific criteria. Most production clinical AI in 2026.
Fine-Tuning Wins When
- The base model demonstrably lacks the specialty reasoning or output style the use case requires.
- Prompt engineering and RAG produce metrics that are demonstrably insufficient.
- The use case has volume sufficient to amortize the fine-tuning investment.
- The output format or behavior pattern is consistent enough across cases that fine-tuning can encode it stably.
- The institution can support the operational overhead (training data preparation, retraining, version validation).
Typical examples. Specialty-specific clinical reasoning where the base model is demonstrably weak. High-volume narrow tasks where a fine-tuned smaller model beats frontier inference economics. Specific output formats where prompt engineering produces unstable structure.
The Hybrid Pattern Most Production Deployments Use
Production healthcare AI in 2026 typically combines techniques rather than using one in isolation.
The dominant pattern. Prompt engineering specifies the use case, the output format, and the few-shot examples. RAG provides institutional grounding through retrieval. Fine-tuning is absent or limited to specific narrow components.
A specialty-tuned variant of the dominant pattern. Prompt engineering plus RAG plus a small fine-tuned classifier model that handles a specific narrow task within the larger pipeline (intent classification, severity scoring, document routing). The fine-tuned component is much narrower than full-feature fine-tuning; the cost and operational overhead are much lower.
The full hybrid for high-volume specialty deployments. Prompt engineering for use case definition, RAG for institutional grounding, fine-tuning of the foundation model for specialty reasoning. Reserved for the highest-volume specialty deployments where the engineering investment amortizes over millions of inferences per year.
The pattern matches the cost-vs-accuracy tradeoff. Prompt engineering plus RAG handles 80–90% of healthcare AI use cases. The hybrid full-stack handles the remaining 10–20% where the additional engineering investment is justified.
What Most Teams Get Wrong
Five common mistakes in customization technique selection.
Mistake 1 — Defaulting to Fine-Tuning
A team assumes fine-tuning is the “real” customization technique and the other two are placeholder. Fine-tuning becomes the project’s centerpiece. The engagement runs 6+ months, costs 5–10x what RAG would have cost, and produces accuracy that prompt engineering plus RAG would have matched in 4 weeks. Resolution: fine-tuning is a last resort, not a default.
Mistake 2 — Skipping Prompt Engineering Rigor
A team treats prompt engineering as “anyone can do it” and skips the rigorous iteration. The baseline accuracy is artificially low; subsequent decisions to add RAG and fine-tuning are based on the wrong baseline. Resolution: rigorous prompt engineering is the foundation of the customization decision; the baseline accuracy here determines whether the next steps are needed.
Mistake 3 — Over-Investing in Custom Retrieval
A team builds a sophisticated custom retrieval pipeline (multi-stage retrieval, reranking, multi-hop reasoning) before validating that simpler retrieval would work. The engineering investment compounds; validation comes too late. Resolution: start with simple retrieval (single-stage vector search), evaluate, add complexity only when the simple version is demonstrably insufficient.
Mistake 4 — Static Corpus
The RAG corpus is built once and treated as fixed. Six months later, guidelines have updated, protocols have changed, and the corpus is stale. Hallucination behavior gets worse over time. Resolution: corpus refresh cadence is operational scope from week 1.
Mistake 5 — Fine-Tuning Without Validating That RAG Was Insufficient
A team commits to fine-tuning before running the eval that would prove RAG is insufficient. The fine-tuning effort completes; comparison to RAG shows the fine-tuning produced marginal accuracy gain at 5–10x the cost. Resolution: validate the simpler technique’s ceiling before committing to the more expensive technique.
Closing
The customization decision in healthcare LLMs is settled by the 2026 production patterns: prompt engineering as the foundation, RAG as the dominant pattern for institutional grounding, fine-tuning as a narrow last-resort reserved for use cases where the simpler techniques are demonstrably insufficient. The cost ratios across the three techniques are large; the accuracy gains across them are not always proportional. Most production healthcare AI is best served by prompt engineering plus RAG.
Teams that internalize this framework ship production AI in 12–16 weeks. Teams that default to fine-tuning ship in 32–52 weeks at 5–10x the cost, often producing the same accuracy as the simpler techniques would have delivered.
If you are scoping a healthcare LLM customization decision and want a partner who applies the framework rigorously, book a 60-minute scoping call. Taction Software has shipped 785+ healthcare implementations since 2013, with 200+ EHR integrations across Epic, Cerner-Oracle, Athena, and Allscripts, zero HIPAA findings on shipped software, and active BAA paper trails with every major AI provider. Our healthcare engineering team operates the prompt engineering plus RAG pattern as default scope on most clinical AI engagements, with fine-tuning added only when validation demonstrates the simpler techniques are insufficient. Our verified case studies cover the production deployments behind these patterns. For the engineering scope behind the engagement, see our healthcare software development practice and our hospital and health-system practice for the operational context. For the data integration patterns this work depends on, see our healthcare data integration practice. For an estimate against your specific use case, see the healthcare engineering cost calculator. For deeper context, see our broader generative AI healthcare applications work.