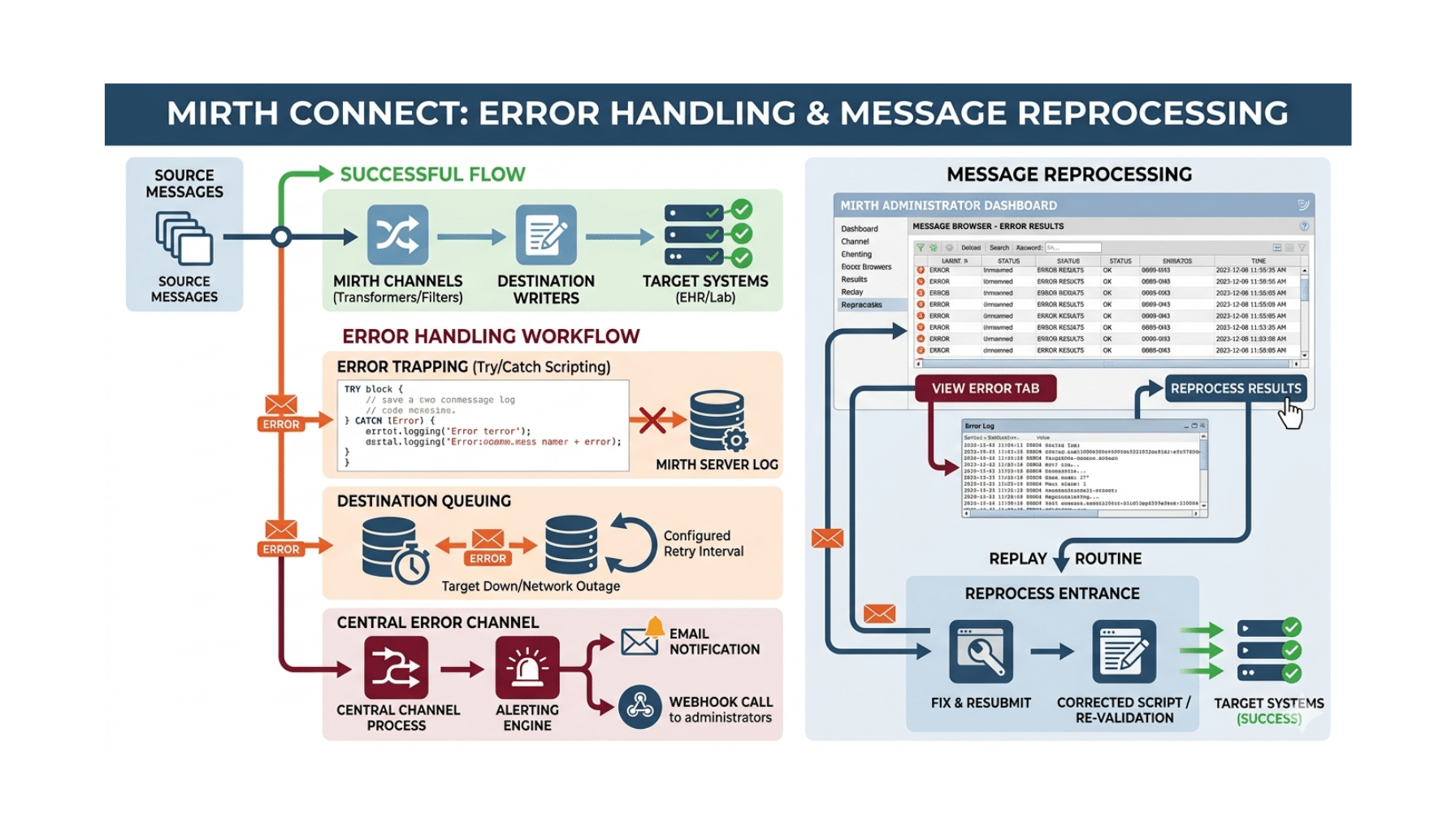
The three frontier closed-model families used in production healthcare AI in 2026 are OpenAI’s GPT family (GPT-4, GPT-4o, o-series reasoning models), Anthropic’s Claude family (Claude 3.5/3.7/4 Sonnet, Claude 3.5/3.7/4 Opus, Haiku), and Google’s Gemini family (Gemini Pro, Gemini Flash, specialty Med-PaLM variants). Selection between them in healthcare contexts depends on six factors: clinical reasoning quality on the specific use case, BAA coverage and contracting path, latency and cost economics at projected scale, output structure and grounding capability, multi-modal capability if the use case requires it, and integration with the customer’s existing cloud and identity infrastructure. No single model dominates across all dimensions; production deployments often use multiple models, routed by an inference gateway based on use-case fit. The selection framework below structures the decision against the criteria that actually matter for healthcare-specific performance.
The “which model” question in healthcare AI has matured from “whichever had the best public benchmark last week” to a structured engineering decision against use-case-specific criteria. The frontier models converge on most general capability metrics; the divergence happens on healthcare-specific dimensions — clinical reasoning quality on specialty content, hallucination behavior under clinical pressure, output grounding, BAA coverage, and integration depth.
This guide is the model-selection framework Taction Software® uses on healthcare AI engagements. It is honest about where each model family is strongest and where each has gaps. The framework is the same one we apply on every model selection decision — including engagements where the answer ends up being “use multiple models routed by use case” or “deploy open-source on-prem instead of any of the closed frontier models.”
The Selection Framework: Six Dimensions
The dimensions that determine the right model for a specific healthcare AI use case at a specific organization.
Dimension 1 — Clinical Reasoning Quality on the Use Case
Generic LLM benchmarks (MMLU, HellaSwag, ARC) do not predict clinical reasoning performance reliably. The relevant question is: how does the model perform on the customer’s specific use case data, with the customer’s specific clinical reviewer rating outputs against the customer’s specific gold standard.
The eval is the only reliable signal. Run the same prompts and the same data through GPT-4, Claude, and Gemini variants. Have the same clinical reviewer rate outputs blinded to model identity. The numbers from this eval are the right basis for selection.
What the production patterns suggest in 2026. The frontier closed models are roughly comparable on most clinical reasoning tasks. Differences exist at the margins — Claude often produces longer-form clinical documentation that aligns well with structured note formats; GPT-4 family handles structured output schemas reliably across the o-series; Gemini’s long-context capability fits use cases involving full chart review. The differences are real but rarely large enough to override other selection dimensions.
Dimension 2 — BAA Coverage and Contracting Path
The most consequential dimension for production deployments. Coverage varies materially across providers and across contracting paths.
OpenAI BAA coverage. Direct API at enterprise tier under ZDR configuration. ChatGPT Enterprise. Excludes consumer products, beta features, and (variably) the Assistants API and tool-using features. Configuration must be confirmed per endpoint.
Anthropic BAA coverage. Three paths — direct, AWS Bedrock, Google Vertex AI. The hyperscaler paths often the faster contracting route for hospitals already on AWS or GCP. Coverage extends to the Claude API endpoints under each path with feature-specific provisions.
Google Vertex AI BAA coverage. Google Cloud healthcare BAA covers Vertex AI inference for Gemini models and the hosted versions of partner models. Med-PaLM and clinical-tuned variants have specific availability terms.
Practical implication. The customer’s existing BAA paper trail often determines the practical model selection more than the model’s technical capability. A customer already on AWS with the existing AWS BAA can use Bedrock-hosted Claude or Llama with no new contracting; a customer on Microsoft can use Azure OpenAI similarly. The contracting path is often more decisive than the model itself.
Dimension 3 — Latency and Cost Economics at Projected Scale
For high-volume use cases — ambient documentation, clinical copilots at enterprise scale, RPM data processing — the per-inference economics compound substantially. Frontier models cost roughly 5–20x what smaller variants cost; the right tier-down for the use case can produce 80%+ cost savings without unacceptable accuracy loss.
The 2026 cost landscape for clinical use cases.
- Frontier-tier models (Claude Opus, GPT-4 family, Gemini Pro): premium pricing, premium capability. Right for use cases where the marginal accuracy gain produces material clinical or operational value.
- Mid-tier models (Claude Sonnet, GPT-4o, Gemini Flash): substantial cost reduction with capability sufficient for many production use cases. The default choice for high-volume clinical documentation, coding assistance, and patient messaging.
- Smaller variants (Claude Haiku, GPT-4o-mini, Gemini Flash variants): further cost reduction; appropriate for narrow well-defined tasks (classification, simple structured generation, routing).
The decision to tier down is empirically validated. Run the same eval at multiple model tiers; if the smaller model meets the accuracy bar, the smaller model is the right answer.
Latency considerations. Interactive use cases (clinical copilots, ambient documentation) require sub-second to a few-second latency. Frontier reasoning models with extended thinking sometimes don’t meet these latency targets; mid-tier models do. The latency-vs-capability trade-off is part of the selection decision.
Dimension 4 — Output Structure and Grounding Capability
Clinical AI requires structured output. Free-text generation that violates the schema (a structured note that omits a required section, a coding suggestion missing the code rationale, a triage disposition without the protocol citation) produces operational friction.
The capabilities to evaluate:
- JSON-mode and structured output enforcement. All three frontier families support enforced structured output, but with different reliability levels. Run the eval on the use case’s actual output schema.
- Citation grounding. Some prompting patterns produce outputs that cite source documents reliably; others don’t. RAG-grounded clinical AI depends on this; the selection decision is downstream of the prompt-engineering iteration.
- Tool-calling reliability. For agentic patterns (the model invokes a calculator, retrieves from a knowledge base, queries a structured data source), tool-calling reliability varies across model families and across versions within families.
- Refusal patterns. Healthcare-content refusals (the model declines to answer a clinical question because the prompt looks like medical advice) vary across providers. Some providers’ default behavior is more conservative than others; system prompts can usually adjust the behavior, but the default matters.
Run the eval. The numbers settle this.
Dimension 5 — Multi-Modal Capability (When Required)
For use cases involving imaging interpretation, voice processing, or document OCR, multi-modal capability becomes the binding constraint.
Imaging-AI-adjacent use cases. GPT-4o, Gemini Pro, and Claude all process images, but the clinical-grade imaging AI use case typically requires specialty models (FDA-cleared imaging products) rather than frontier closed models. Frontier models are useful for imaging-related text reasoning (drafting reports from extracted findings, summarizing imaging history) rather than for primary imaging interpretation.
Voice-processing use cases. Ambient documentation requires high-quality medical-domain ASR (automatic speech recognition) — a separate model component from the LLM that drafts the structured note. The LLM choice happens after the ASR; the multi-modal evaluation is on the LLM’s handling of medical terminology, abbreviations, and clinical structure rather than on its ASR capability.
Document OCR. Frontier models handle document OCR reasonably well; specialized OCR models often outperform on poor-quality scans, faxes, and handwritten notes. The choice depends on document quality.
Dimension 6 — Integration with Existing Cloud and Identity Infrastructure
The model that operates inside the customer’s existing identity provider, cloud platform, and data infrastructure is operationally easier to deploy than a model that requires a new vendor relationship and a parallel infrastructure path.
Customer on AWS: Bedrock-hosted Claude or Llama is the operationally simplest path.
Customer on Microsoft/Azure: Azure OpenAI is the operationally simplest path.
Customer on Google Cloud: Vertex AI (Gemini, Claude via partnership, Med-PaLM where available) is the operationally simplest path.
Customer not standardized on any single hyperscaler: Direct provider relationships make sense. The contracting and infrastructure work is higher; the flexibility is also higher.
Use Case Mapping
The mapping Taction’s engineering team uses on most engagements. The mapping is not absolute — eval-driven selection always overrides the default.
Ambient clinical documentation: Claude (via direct API or hyperscaler path) is often the default for the structured-note generation, paired with a medical-domain ASR model for the voice front-end. GPT-4 family and Gemini are also strong; the differentiator is often contracting path.
Clinical copilots (triage, coding, prior auth): GPT-4o or Claude Sonnet for high-volume use cases; Claude Opus or GPT-4-class reasoning models for higher-acuity clinical decision support where the marginal accuracy matters.
Predictive analytics: Frontier LLMs are not typically the right tool. Predictive ML uses purpose-trained models (gradient boosting, deep learning on tabular data, time-series models). LLMs come in for the explanation and rendering layer, not the prediction itself.
Generative AI for population analysis or research: Long-context models (Gemini Pro, Claude Opus) for large-corpus reasoning; mid-tier models for high-volume per-case generation.
Patient-facing AI (messaging, education content): Mid-tier models (Sonnet, GPT-4o) with strong content-safety controls. Frontier reasoning capability is rarely needed; safety and tone matter most.
On-prem deployment requirements: None of the three frontier closed models. Llama 3 70B, Mistral, Phi-3, or Qwen on customer-controlled infrastructure. The trade-off is capability slightly behind frontier (one to two model generations) for full data control.
What Most Teams Get Wrong
Five common mistakes in model selection.
Mistake 1 — Selecting Based on Public Benchmarks Alone
Public benchmarks measure the things that benchmark authors decided to measure. The customer’s specific use case, on the customer’s specific data, with the customer’s specific gold standard, is what matters. Run the eval.
Mistake 2 — Locking In Without Testing Multiple Models
Most production healthcare AI deployments benefit from multi-model architecture — different use cases route to different models based on fit. Locking in to a single model from week 1 forecloses the optimization that the inference gateway makes possible.
Mistake 3 — Defaulting to the Most Capable Model for Every Use Case
Frontier reasoning models are 5–20x the cost of mid-tier alternatives. Most clinical use cases don’t need frontier capability — they need consistent capability matched to the use case requirements. The right tier-down produces substantial cost savings without accuracy loss.
Mistake 4 — Underestimating Contract and Integration Friction
A “better” model that requires 8 weeks of new vendor contracting and parallel infrastructure deployment is often worse than an “adequate” model the customer can deploy in week 1. The contracting path matters operationally more than the marginal capability gain.
Mistake 5 — Building the Architecture for One Model
The inference gateway pattern abstracts the specific model. Application code calls the gateway with use-case parameters; the gateway routes to the appropriate model based on configuration. This pattern lets the customer switch models without rewriting application code, route different use cases to different models, and run A/B tests across models cleanly.
The Engineer’s Decision Process
The decision process Taction’s team applies on every model selection.
Step 1 — Confirm the BAA contracting path. Which model providers are in the customer’s existing BAA paper trail or are operationally accessible. This narrows the field before capability evaluation.
Step 2 — Identify the use case requirements. Output structure, latency, cost economics at scale, multi-modal needs, regulatory constraints. The requirements define the candidate set.
Step 3 — Run the eval on multiple candidates. Same prompts, same data, same gold standard, blinded clinical reviewer. The numbers settle the decision.
Step 4 — Build for multi-model architecture. The inference gateway abstracts the specific model. Future use cases route to whichever model fits best. The architecture decision is more important than the initial model decision.
Step 5 — Re-evaluate annually. Frontier model capabilities change. The model that was right in 2026 may not be right in 2027. The architecture that supports easy re-evaluation makes that change tractable.
Closing
OpenAI, Anthropic, and Google all offer frontier closed models suitable for production healthcare AI in 2026. The right model for any specific use case at any specific organization depends on six dimensions — clinical reasoning quality, BAA coverage, latency and cost, output structure, multi-modal capability, and integration with existing infrastructure. No single model dominates across all dimensions; the right architecture is multi-model with use-case-based routing.
The teams that select on this framework produce production deployments with appropriate cost economics, contracting paths, and capability matched to the use case. The teams that select on benchmark scores or vendor marketing produce deployments that need re-platforming within 12 months.
If you are running a model selection for a healthcare AI engagement and want a partner who runs the eval-driven decision framework, book a 60-minute scoping call. Taction Software has shipped 785+ healthcare implementations since 2013, with 200+ EHR integrations across Epic, Cerner-Oracle, Athena, and Allscripts, zero HIPAA findings on shipped software, and active BAA paper trails with every major AI provider. Our healthcare engineering team operates the inference gateway pattern with multi-model routing as default scope on enterprise engagements. Our verified case studies cover the production deployments behind these patterns. For the engineering scope behind the engagement, see our healthcare software development practice and our hospital and health-system practice for the operational context. For the data integration patterns this work depends on, see our healthcare data integration practice. For an estimate against your specific use case, see the healthcare engineering cost calculator. For deeper context, see our broader generative AI healthcare applications work.