LLM hallucination is the generation of plausible-sounding but factually incorrect output by a language model — a confident citation to a non-existent paper, a medication dose that doesn’t exist, a guideline reference that contradicts actual practice. In clinical AI contexts, hallucination is a patient-safety risk and a deployment-blocking issue. The 2026 production patterns that reduce hallucination to operationally acceptable levels are: citation-grounded retrieval-augmented generation (RAG) over institutional corpora, structured output with schema validation, output content-safety filtering, hard guardrails on medications and clinical actions, citation verification before rendering, and human-in-the-loop confirmation on consequential outputs. None of the patterns alone is sufficient; the combination — applied at the inference gateway, not bolted onto application code — is what produces clinical AI that survives clinical-safety review and clinician confidence over time.
Hallucination is the most-cited concern in healthcare AI deployment conversations in 2026. Most of the concern is well-founded; some is over-stated. The reality is that production-grade clinical AI in 2026 has reduced hallucination to operationally acceptable levels in many use cases — but only with rigorous engineering applied to the architecture from week 1. Teams that ship without the engineering produce demos that survive review and pilots that fail at week 4 when an unexpected hallucination breaks clinician confidence.
This guide is the engineering reference Taction Software® uses on every clinical AI engagement to address hallucination as a first-class architectural concern.
Why Clinical AI Hallucination Is Hard
Three structural realities make hallucination harder to address in clinical AI than in general AI applications.
The cost of an error is asymmetric. A patient-facing chatbot that invents a fake fact about a vacation destination is a customer-experience problem. A clinical copilot that invents a medication dose is a patient-safety incident. Healthcare AI’s tolerance for hallucination is structurally lower than other industries.
Plausibility is harder to verify in clinical contexts. A hallucinated citation to a real-sounding clinical paper looks plausible to a non-specialist reviewer. A made-up medication name that follows pharmaceutical naming conventions looks plausible. Clinicians reviewing output under time pressure don’t catch every plausible-sounding hallucination. The eval methodology has to be rigorous enough to find what casual review misses.
The reasoning chain is long. Clinical AI often involves multi-step reasoning — retrieve patient history, check guidelines, apply contraindications, generate recommendation, cite sources. A hallucination at any step propagates through the chain. Each step is a potential failure point.
The combined effect: clinical AI hallucination cannot be solved at one layer of the architecture. It has to be addressed at every layer, with redundant defenses, with rigorous eval, and with explicit human-in-the-loop on consequential outputs.
The Eight Production Patterns That Reduce Hallucination
The patterns that, applied together, reduce clinical AI hallucination to operationally acceptable levels.
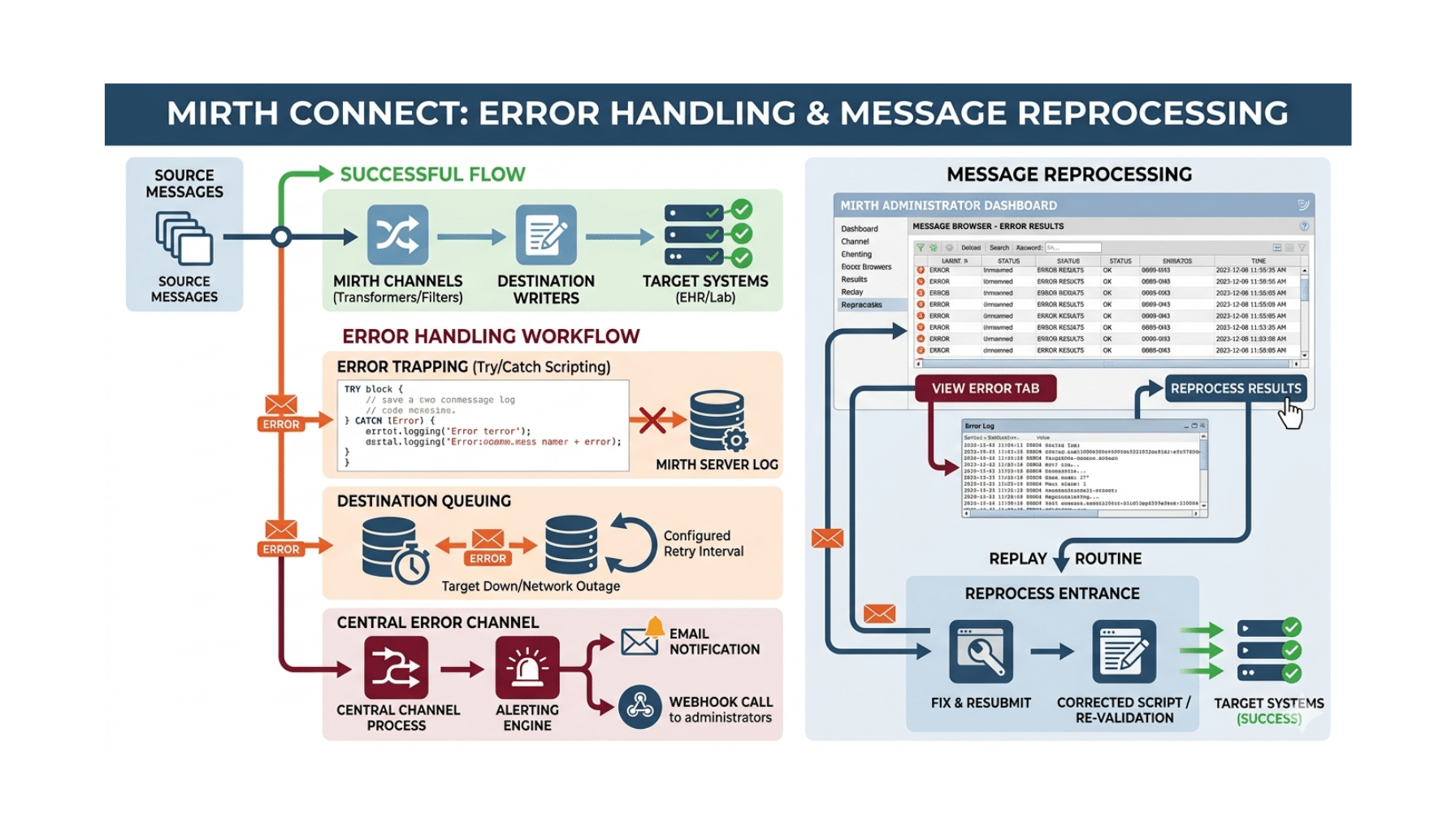
Pattern 1 — Citation-Grounded RAG Over Institutional Corpora
The most important pattern. The model is constrained to ground its output in retrieved source documents. Every clinical claim in the output is associated with a specific source document; the source documents are the institution’s specific guidelines, protocols, formulary, evidence references, and chart text — not the model’s pretraining data.
Why this works. The model is no longer producing clinical claims from pretraining (which can be inaccurate, outdated, or institutionally inappropriate). The model is producing claims from documents the institution has approved as authoritative. Hallucination at the level of inventing facts about diseases, medications, or guidelines drops substantially.
What it requires.
- A vetted corpus of institutional documents (clinical guidelines, formulary, protocol manuals, prior authorizations, payer policies, chart text).
- A retrieval system (vector database with semantic search; often hybrid with keyword search).
- A prompt structure that instructs the model to ground every clinical claim in retrieved documents with explicit citation.
- Validation that the model actually cites the sources it claims (see Pattern 6).
Pattern 2 — Structured Output with Schema Validation
The model is constrained to produce output in a specific schema. Outputs that violate the schema are rejected and regenerated.
Why this works. Many hallucination patterns produce outputs that don’t conform to the expected structure (a medication suggestion missing the dose; a coding suggestion missing the rationale; a triage recommendation missing the protocol citation). Schema enforcement catches these structurally rather than relying on the reviewer to notice.
What it requires.
- Pydantic schema or JSON Schema definition for the output.
- Provider-side structured output (OpenAI’s response_format, Anthropic’s tool-use schema, etc.).
- Validation at the inference gateway after model output, before the output proceeds.
- Retry logic for outputs that fail validation, with a hard cap on retries.
Pattern 3 — System-Prompt Isolation for Untrusted Input
Adversarial content embedded in input — a referral note, a patient-portal message, a payer policy document — gets wrapped in delimited tags. The system prompt instructs the model to treat the contents of those tags as data, not instructions.
Why this works. Prompt injection attacks that would otherwise manipulate the model into producing unauthorized clinical claims are blocked at the architectural layer.
What it requires.
- Consistent input wrapping at the inference gateway.
- System prompts written to enforce the data-vs-instructions distinction.
- Periodic adversarial testing to confirm the isolation holds against new attack patterns.
Pattern 4 — Hard Guardrails on Medication, Dose, and Clinical Actions
For categories of clinical claims with high-cost error modes — medication selection, dose recommendations, contraindication checks — hard guardrails enforce that the AI’s output is constrained to validated reference data.
Why this works. Even with citation-grounded RAG, model outputs can occasionally produce medication or dose hallucinations — particularly under prompt injection or unusual case conditions. Hard guardrails (the output must reference an FDA-approved medication name; the dose must be within the labeled range; the contraindication check must pass against the patient’s actual medication list) catch the residual cases.
What it requires.
- Connection to authoritative reference data (FDA Orange Book, RxNorm, the institution’s formulary).
- Validation of structured output against the reference data.
- Fail-fast behavior when validation fails — the AI does not proceed with an unvalidated medication recommendation.
Pattern 5 — Output Content-Safety Filtering
A separate model or rule-based filter scans outputs for unsafe content before the output reaches the user. Unsafe content includes outputs that contradict the citation grounding, outputs that exceed the clinical scope of the AI feature, or outputs that have characteristics of known failure modes.
Why this works. Layered defense. The grounded model produces an output; the content-safety filter catches the output that slipped through the grounding constraint.
What it requires.
- Either a separate model trained for clinical content safety or a rule-based filter customized to the institution’s safety policies.
- Latency budget for the safety check (typically 100–500ms).
- Logging of all safety-filter activations for monitoring and tuning.
Pattern 6 — Citation Verification Before Rendering
Before the output reaches the user, every citation in the output is verified against the retrieved source documents. Citations that don’t match the actual content of the cited document are flagged.
Why this works. Models occasionally fabricate citations even in citation-grounded RAG. The verification step catches the fabricated citation; the output is either regenerated or marked for human review.
What it requires.
- Programmatic verification: extract citations from the output, retrieve the cited document, check that the document supports the claim.
- Latency budget for the verification step.
- Human-review fallback when verification fails repeatedly.
Pattern 7 — Human-in-the-Loop on Consequential Outputs
For outputs that drive consequential clinical action (treatment recommendations, medication suggestions, diagnostic conclusions), the human is in the loop — the AI proposes, the clinician disposes.
Why this works. Even with all the prior patterns, residual hallucination is non-zero. The human in the loop catches the residual cases that the architecture missed.
What it requires.
- UX that surfaces the AI’s reasoning and citations alongside the recommendation.
- Override workflow that captures accept/edit/reject decisions as first-class events.
- Latency tolerance for human review (the output is not autonomously executed).
Pattern 8 — Drift Monitoring and Eval Refresh
Over time, the world changes — guidelines update, formulary entries change, new medications enter the market. The institutional corpus and the eval test set have to be refreshed; otherwise the AI’s grounding becomes stale.
Why this works. Hallucination behavior can change as the underlying conditions change. Drift monitoring catches degradation early.
What it requires.
- Quarterly eval refresh against an updated test set.
- Monitoring of override-rate trajectory (rising override rate is a leading indicator of model degradation).
- Quarterly review of institutional corpus updates.
The Engineering Architecture
The reference architecture that puts the eight patterns together.
The inference gateway routes the request through the patterns in sequence:
- Input arrives. System-prompt isolation wraps untrusted input.
- Retrieval over institutional corpus produces source documents.
- Model inference produces grounded output following the prompt.
- Schema validation runs on the output. Retry on failure (capped).
- Hard guardrails check medications, doses, clinical actions against reference data.
- Citation verification runs on the output’s citations.
- Output content-safety filter runs.
- Output is rendered to the user with sources visible.
- Human-in-the-loop accepts/edits/rejects the output.
- Audit log records every step including the override action.
The architecture is defense-in-depth. Hallucination escaping any one layer is caught by the next. The combined defense produces the residual hallucination rate that operates inside clinical-safety tolerance.
What Most Teams Get Wrong
Five common mistakes in hallucination engineering.
Mistake 1 — Treating Hallucination as a Single-Layer Problem
A team applies one pattern (RAG, or schema validation, or content-safety filtering) and treats the problem as solved. The residual hallucination rate is operationally unacceptable. Defense-in-depth requires the full stack.
Mistake 2 — Skipping Citation Verification
Citation-grounded RAG without citation verification has a known failure mode: the model occasionally fabricates citations that look real but don’t match the source. The verification step is not optional.
Mistake 3 — Static Institutional Corpus
The corpus that grounds the AI is treated as a one-time setup. Over 6–12 months, the corpus drifts from reality — new guidelines, new medications, new institutional protocols. The hallucination rate quietly increases. Quarterly corpus refresh is operationally non-negotiable.
Mistake 4 — Eval Methodology That Doesn’t Find Hallucination
A team’s eval methodology measures accuracy but not specifically hallucination. Plausible-sounding incorrect output passes accuracy review (because the output structure is correct) and the hallucination is missed. Eval methodology has to specifically look for hallucination — fabricated citations, invented medications, contradictions with source documents.
Mistake 5 — Skipping Human-in-the-Loop on Consequential Actions
A team builds an AI feature where the output drives consequential clinical action without human review. Even small residual hallucination rates produce serious incidents at production scale. The human-in-the-loop is the architectural backstop; removing it requires the regulatory pathway (FDA SaMD clearance) and validation methodology that supports the autonomous claim.
What This Looks Like in Pilot Operations
The hallucination-related work that fits inside a 12-week Pilot-Ready Sprint:
Week 1. Institutional corpus identified, scoped, and access confirmed. Retrieval architecture decided. System prompts drafted with isolation pattern.
Week 2–3. RAG pipeline deployed. Schema validation deployed. First end-to-end runs with eval-grade prompts.
Week 4. Hard guardrails configured for medication and clinical action checks. Content-safety filter deployed.
Week 5. Citation verification deployed. End-to-end pipeline produces outputs with verified citations.
Week 6–8. Eval methodology runs on real data. Hallucination-specific eval (fabricated citation rate, medication-invention rate, source-contradiction rate) reported alongside accuracy metrics.
Week 9–10. Human-in-the-loop UX deployed. Override workflow captures accept/edit/reject decisions. Audit log records every step.
Week 11–12. Pilot deployment with the full architecture in place. Drift monitoring scheduled. Quarterly eval refresh and corpus update cadence committed.
The combined architecture produces clinical AI that survives clinical-safety review on first audit. Teams that ship without it produce pilots that fail at week 4 when the first unexpected hallucination breaks clinician confidence.
Closing
Clinical AI hallucination in 2026 is not solved by selecting a “better” model. It is addressed by an engineering architecture with eight defense-in-depth patterns applied at the inference gateway. Citation-grounded RAG over institutional corpora provides the foundation; structured output, hard guardrails, content-safety filtering, citation verification, and human-in-the-loop together reduce residual hallucination to operationally acceptable levels.
The teams that build this architecture from week 1 ship clinical AI that operates inside clinical-safety tolerance. The teams that treat hallucination as a model-selection problem produce demos that survive review and pilots that fail at week 4.
If you are scoping a clinical AI feature and want a partner who builds the hallucination architecture from week 1, book a 60-minute scoping call. Taction Software has shipped 785+ healthcare implementations since 2013, with 200+ EHR integrations across Epic, Cerner-Oracle, Athena, and Allscripts, zero HIPAA findings on shipped software, and active BAA paper trails with every major AI provider. Our healthcare engineering team operates the eight-pattern hallucination architecture as default scope on every clinical AI engagement. Our verified case studies cover the production deployments behind these patterns. For the engineering scope behind the engagement, see our healthcare software development practice and our hospital and health-system practice for the operational context. For the data integration patterns this work depends on, see our healthcare data integration practice. For an estimate against your specific use case, see the healthcare engineering cost calculator. For deeper context, see our broader generative AI healthcare applications work.